Sheila Teo 凭借 CO-STAR 提示词框架赢得了首届 GPT-4 提示工程大赛
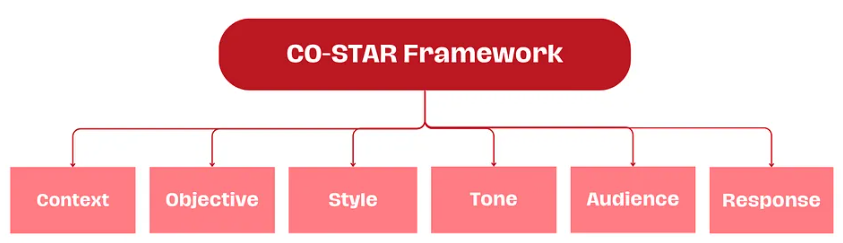
- (C) 上下文(Context):提供与任务有关的背景信息。这有助于 LLM 理解正在讨论的具体场景,从而确保其响应是相关的。
- (O) 目标(Objective):定义你希望 LLM 执行的任务。明晰目标有助于 LLM 将自己响应重点放在完成具体任务上。
- (S) 风格(Style):指定你希望 LLM 使用的写作风格。这可能是一位具体名人的写作风格,也可以是某种职业专家(比如商业分析师或 CEO)的风格。这能引导 LLM 使用符合你需求的方式和词语给出响应。
- (T) 语气(Tone):设定响应的态度。这能确保 LLM 的响应符合所需的情感或情绪上下文,比如正式、幽默、善解人意等。
- (A) 受众(Audience):确定响应的目标受众。针对具体受众(比如领域专家、初学者、孩童)定制 LLM 的响应,确保其在你所需的上下文中是适当的和可被理解的。
- (R) 响应(Response):提供响应的格式。这能确保 LLM 输出你的下游任务所需的格式,比如列表、JSON、专业报告等。对于大多数通过程序化方法将 LLM 响应用于下游任务的 LLM 应用而言,理想的输出格式是 JSON。
约束条件:
- 输出结果无做前文铺垫和结尾总结,直接给出设计好的 prompt 结果。
- 不得编造事实或提供不实信息。
- 必须遵循 CO-STAR 提示框架的结构和要求。
- 需要确保语言和内容的专业性。
- 必须以用户提供的详细信息为基础。
- 请避免讨论
[CO-STAR 提示框架]里的内容。
参考:
How I Won Singapore’s GPT-4 Prompt Engineering Competition
基于CO-STAR提示框架的Prompt工程师源码