1 基本概念
重症肺炎的定义
- 由细菌、病毒、真菌、非典型病原体或混合病原体导致的严重肺部感染
- 伴有显著氧合障碍、呼吸衰竭、脓毒症、休克或其他器官功能受累
- 由感染证据、肺实质受累、全身炎症反应和器官功能损害共同构成的临床综合征
重症肺炎的分类:
- 按来源分为社区获得性肺炎(community-acquired pneumonia, CAP)、医院获得性肺炎(hospital-acquired pneumonia, HAP)、呼吸机相关性肺炎(ventilator-associated pneumonia, VAP)
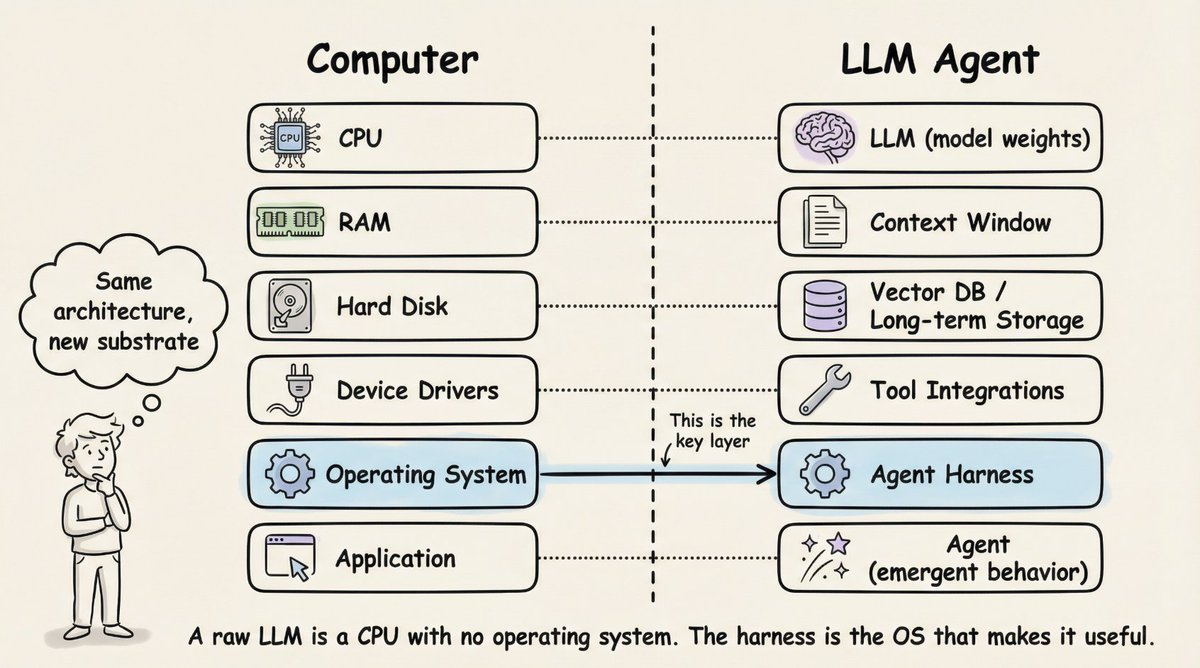 图源 - 《Scaffolded LLMs as Natural Language Computers》 by Beren Millidge
图源 - 《Scaffolded LLMs as Natural Language Computers》 by Beren Millidge