1 基础概念
呼吸治疗:通过一系列手段帮助患者维持正常的呼吸功能。对于危重患者而言,由于疾病或损伤导致自身呼吸功能不足,无法满足身体的氧气需求,因此需要借助外部设备或技术来辅助呼吸。
呼吸治疗的核心目标:在一定时间内给患者最佳呼吸支持包括向重要器官提供 PaO2 为 60-90mmHg,PaCO2<60mmHg 的可行气体交换的动脉血和足够的氧气输送,同时尽量减少不良影响
分类目录归档:学习
呼吸治疗:通过一系列手段帮助患者维持正常的呼吸功能。对于危重患者而言,由于疾病或损伤导致自身呼吸功能不足,无法满足身体的氧气需求,因此需要借助外部设备或技术来辅助呼吸。
呼吸治疗的核心目标:在一定时间内给患者最佳呼吸支持包括向重要器官提供 PaO2 为 60-90mmHg,PaCO2<60mmHg 的可行气体交换的动脉血和足够的氧气输送,同时尽量减少不良影响
前置知识:双重差分法 DID、合成控制法、双向固定效应 TWFE
已知双重差分法 DID 的线性模型可表示如下: $$ Y_{it} = \beta_0 + \beta_1 Post_t + \beta_2 Treated_i + \beta_3 Treated_i Post_t + e_{it} $$
post 表示时间虚拟变量,treated 表示干预虚拟变量而通过引入个体/时间的固定效应,可以将 DID 表示为 TWFE 的形式: $$ \hat{\tau}^{did} = \underset{\mu, \alpha, \
前置知识:因果推断入门
随机实验(Randomised Experiments)
ATE=E[Y|T=1] - E[Y|T=0] = E[Y_1 - Y_0] $$
常见的随机实验:
前置知识:因果效应评估_准实验、因果效应评估_异质性 、双重机器学习 DML
双向固定效应(Two Way Fixed Effect,TWFE)
当出现不同组的干预时间不同的情况,即错位实施(Staggered Adoption),TWFE 对干预效应的评估容易存在偏差,尤其是干预效应存在时间异质性的情况
简单来说,TWFE 会将早期干预组的干预效应
前置知识:因果效应评估_配平法、因果效应评估_异质性 、因果效应评估_元学习
双重机器学习 (Double Machine Learning, DML):利用机器学习强大的预测能力,先剔除 X 对 T 的影响,再剔除 X 对 Y 的影响,最后看残差之间的关系。
DML 的实现过程:
SOAP (Subjective, Objective, Assessment and Plan)记录
主观描述(Subjective):患者或其亲属的“主观”经历、个人观点或感受
元学习
S 学习器(S-Learner)是一种最简单的元学习方法
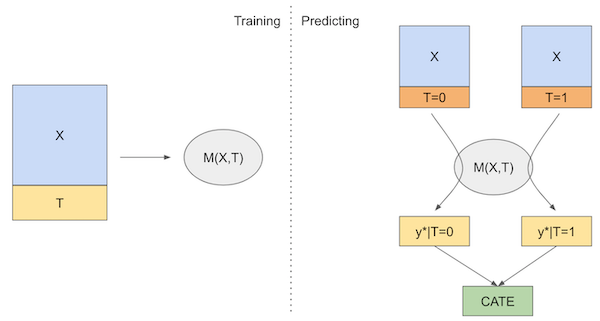
$$ \hat{\tau}(
定义外生变量为 $X$,干预变量为 $T$,评估异质性干预效应的公式如下: $$ \underset{T}{argmax} \ E[Y|X, T] $$
估计条件平均干预效应(CATE),以
因果效应评估之配平法
配平法的常见算法:回归调整、倾向得分匹配、熵平衡、双重稳健估计
虚拟回归(Regression for Dummies)
缺点:建模能力弱,只能捕捉到变量之间的线性关系
异方