图表示学习方法一般包括图嵌入表示和图神经网络
- 图嵌入表示(Node Embedding)为每个节点学习一个嵌入表示(低维稠密向量),使得在原始网络中相似的节点,它们的嵌入表示也更为相似
- 图神经网络(Graph Neural Networks)通过聚合邻域节点的信息来生成节点的表示
图嵌入表示
基于随机游走的图嵌入经典方法:
- 等长度、无偏的随机游走:DeepWalk (2014 KDD Perozzi et al.)
- 有偏
分类目录归档:学习
循环神经网络(RNNs):具有隐状态、不同层参数共享的神经网络
常见的三种基础 RNNs :RNN、GRU、LSTM
隐变量模型:使用隐状态 $h_{t-1}$ 存储前 $t-1$ 步的序列信息 $$P(x_t|x_{t-1},...,x_1)\approx P(x_t|h_{t-1})$$ $$h_t=f(x_t,h_{t-1})$$ 循环神经网络(recurrent neural networks,RNNs) 是具有隐状态的神经网络
假设时刻 $t$ 的输入为 $X_t \in \mathbb{R}^{n\times d}$,对应的权重参数为 $W
卷积神经网络(CNN):引入了卷积操作的神经网络
严格来说,卷积层是个错误的叫法,因为它所表达的运算其实是互相关运算(cross-correlation)
二维互相关运算示例:
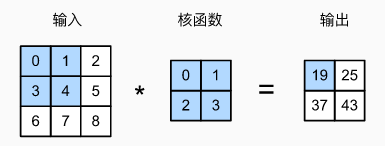
池化(pool)层的优点:降低卷积层对位置的敏感性
常用池化层分两种:最大池化层和平均池化层,前者示例如下:

类似于卷积层,池化层也会有填充和步幅,使用大于 1 的步幅可以起到降维的作用
不同于卷积层,池化层在每个输入通道上是单独计算的,所以池化层的输出通道数等于输入通道数
膨胀(dilated)卷积,也称
均值回归:对历史一段时间的值取平均,作为未来每个时刻的预测
指数平滑:预测值是过去一段时间内观测值(或已预测值)的加权平均值
普通回归预测:借助时序相关特征(如节假日、周期性)实现建模预测
更多的时序类衍生特征可参考 1_study/Python/Python 数据处理/tsfresh 时序特征聚合工具
自回归(AR)模型:
常见的镇静药物包括巴比妥类药物和非巴比妥类药物。后者主要包括苯二氮䓬类药物、丙泊酚、依托咪酯、右美托咪定和环泊酚等。镇静药物通过多种机制影响神经递质的释放、再摄取和代谢,以抑制中枢神经系统的兴奋性,从而产生镇静效应
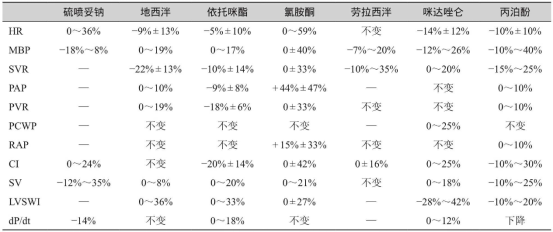
各类常见镇静麻醉药物应用于麻醉诱导后血流动力学变化:
术后肺部并发症(postoperative pulmonary complications, PPCs)是术后呼吸系统相关并发症的统称,是导致患者术后住院时间延长、医疗费用和病死率增加的重要原因之一。
定义:PPCs 可视为一种复合结局指标,主要包括肺不张、气胸、呼吸道感染、呼吸衰竭、胸腔积液、肺炎、急性呼吸窘迫综合征(acute respiratory distress syndrome, ARDS)、肺栓塞等,目前尚无统一的定义。临床中主要包括4种常见的诊断方案。
高达 40%的患者在心脏手术后会出现术后肺部并发症(PPC),仅次于心血管并发症
GLUE(General Language Understanding Evaluation,通用语言理解评估)是一种常用的评估工具,用于评估 NLP 模型在一系列任务上的有效性。
GLUE 基准测试由纽约大学和谷歌的研究人员开发的。开发 GLUE 的动机是需要一个全面的 NLP 模型评估框架,该框架测试语言理解的不同方面并提供更完整的描述
官网为: https://gluebenchmark.com/
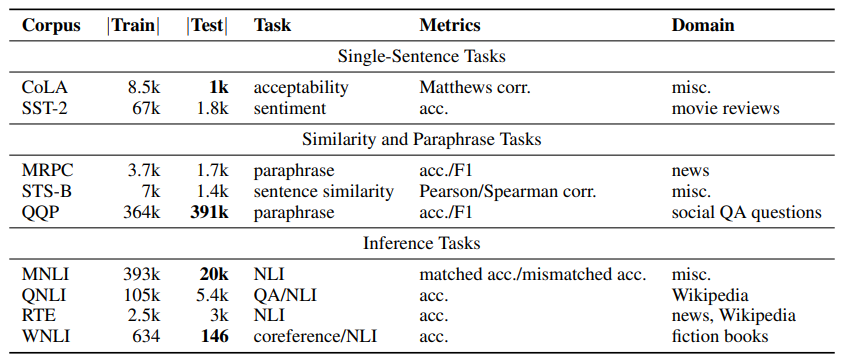
GLUE 共包含 3 个分类 9 个任务:
上下文无关文法(context-free grammar,CFG):
CFG的形式化定义可以表示为一个四元组 $G=(V,T,P,S)$
常用指令:
pip install sampleproject
pip install sampleproject==1.0.4 # 指定版本
pip