仅搜集收录了部分个人感兴趣的文章,并进行简单记录
发表评论
1931 views
仅搜集收录了部分个人感兴趣的文章,并进行简单记录
常见的镇静药物包括巴比妥类药物和非巴比妥类药物。后者主要包括苯二氮䓬类药物、丙泊酚、依托咪酯、右美托咪定和环泊酚等。镇静药物通过多种机制影响神经递质的释放、再摄取和代谢,以抑制中枢神经系统的兴奋性,从而产生镇静效应
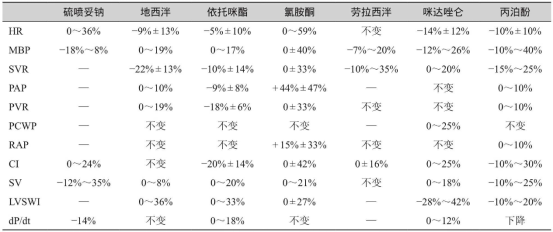
各类常见镇静麻醉药物应用于麻醉诱导后血流动力学变化:
术后肺部并发症(postoperative pulmonary complications, PPCs)是术后呼吸系统相关并发症的统称,是导致患者术后住院时间延长、医疗费用和病死率增加的重要原因之一。
定义:PPCs 可视为一种复合结局指标,主要包括肺不张、气胸、呼吸道感染、呼吸衰竭、胸腔积液、肺炎、急性呼吸窘迫综合征(acute respiratory distress syndrome, ARDS)、肺栓塞等,目前尚无统一的定义。临床中主要包括4种常见的诊断方案。
高达 40%的患者在心脏手术后会出现术后肺部并发症(PPC),仅次于心血管并发症
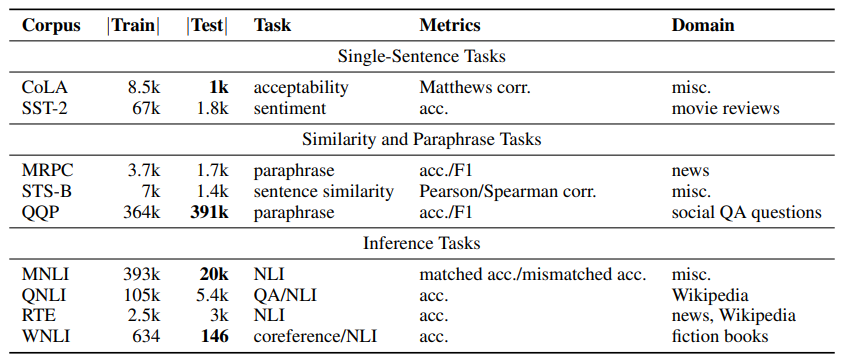
GLUE(General Language Understanding Evaluation,通用语言理解评估)是一种常用的评估工具,用于评估 NLP 模型在一系列任务上的有效性。
GLUE 基准测试由纽约大学和谷歌的研究人员开发的。开发 GLUE 的动机是需要一个全面的 NLP 模型评估框架,该框架测试语言理解的不同方面并提供更完整的描述
官网为: https://gluebenchmark.com/
GLUE 共包含 3 个分类 9 个任务:
光流(Optical Flow)是计算机视觉中的一个重要概念,它主要描述的是图像序列中像素在时间维度上的运动变化。
简单来说,光流就是在连续的两帧图像之间,每个像素点的运动速度和方向。
光流的计算基于这样一个假设:在短时间内,连续的图像帧之间,像素的颜色值不会发生显著的变化。基于这个假设,我们可以通过比较连续的两帧图像,来计算出像素点在这两帧之间的运动。
光流有很多应用,例如在视频处理中,可以用来进行运动检测、物体跟踪等;在自动驾驶和机器人领域,可以用来进行场景理解、导航和避障等。
光流问题的主要挑战在于,它是一个典型的病态问题,即小的测量误差可能导致结果的巨大变化,因此需要采用复杂的优化
上下文无关文法(context-free grammar,CFG):
CFG的形式化定义可以表示为一个四元组 $G=(V,T,P,S)$
预印本