图训练的完整 Pipeline:
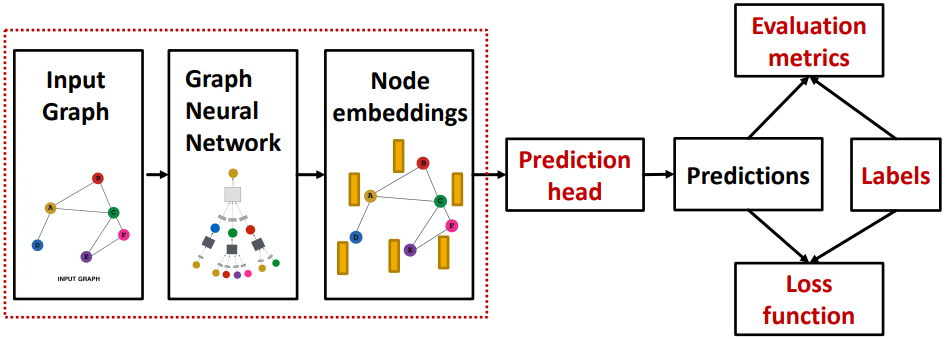
1 GNN 的预测
不同的任务级别需要不同的预测头(Prediction head)
- 节点(node-level)级预测:直接使用 $d$ 维的节点嵌入 $h_v^{(L)}$ 进行预测
$$ \widehat{\boldsymbol{y}}_v=\mathrm{Head}_{\mathrm{node}}(\mathbf{h}_v^{(L)})=\mathbf{W}^{(H)}\mathbf{h}_v^{(L)} $$
- 边(edge-level)级预测:使用成对的节点嵌入进行预测
$$ \widehat{\boldsymbol{y}}_v=\mathrm{Head}_{\mathrm{edge}}(\mathbf{h}_u^{(L)},\mathbf{h}_v^{(L)})=Liner(Concat(\mathbf{h}_u^{(L)},\mathbf{h}_v^{(L)})) $$
除了以上方式,$\mathrm{Head}_{\mathrm{edge}}$ 函数还可以使用点积的形式:$(\mathbf{h}_u^{(L)})^T\mathbf{h}_v^{(L)}$
- 图(graph-level)级预测:使用图中所有的节点嵌入进行预测
$$ \widehat{\boldsymbol{y}}_G=\mathrm{~Head}_{\mathrm{graph}}({\mathbf{h}_v^{(L)}\in\mathbb{R}^d,\forall v\in G}) $$
其中常见的 $\mathrm{Head}_{\mathrm{graph}}$ 聚合函数包括 Mean、Max、Sum
2 GNN 的标签
GNN 的标签(labels)主要分为有监督和无监督两种情况
有监督学习的标签一般来自外部标注
- 节点标签 $y_v$:引文网络中,每篇论文(节点)属于哪个主题分类?
- 边标签 $y_{uv}$:交易网络中,两个用户之间的交易流水(边)是否存在欺诈行为
- 图标签 $y_G$:药物分子图中,不同药物(图)间的相似性度量
- 实践中,尽量将外部信息转化为以上三种形式(比如节点集群信息转化为节点标签)
无监督学习的标签一般来自图表本身,又称自监督
- 节点标签 $y_v$:节点的统计信息,比如聚类系数、PageRank 等
- 边标签 $y_{uv}$:随机隐藏两节点之间的边并进行节点间的链接预测
- 图标签 $y_G$:预测两个图是否同构
有监督和无监督的边界是模糊的,比如预测节点的聚类系数
3 GNN 的损失函数
对于分类问题,交叉熵(cross entropy,CE)是常见的损失函数
对于回归问题,均方误差(mean squared error,MSE)是常见的损失函数
更多细节:损失函数
4 GNN 的评价指标
对于回归问题,常见评价指标是 RMSE、MAE
对于分类问题,常见评价指标是准确率、召准率、召回率、AUROC
更多细节:模型评价
图数据集划分:
- 训练集(参数学习)、验证集(模型和超参调整)和测试集(最终性能)
- 图数据集的特殊性:不同数据点之间不是独立的,不能直接切割开
- 解决方案 1:训练/验证阶段都使用完整图计算嵌入,但只考虑部分节点标签
- 解决方案 2:通过边的切割,产生多个子图并分别用于训练集和验证集
- 方案 1(Transductive setting)仅适用于节点/边预测任务,不适用于图预测任务
- 方案 2(Transductive setting)同时适用于节点/边/图预测任务, 泛化性更强