前置知识:强化学习入门、Deep Q-Learning
策略梯度算法
策略梯度(Policy Gradient)
基于价值(Value Based)方法的局限性:
- 离散动作空间,难以处理连续或高维的动作空间
- 受限状态下的问题,可能不存在基于价值的最优解
- 基于最大价值的策略为确定性策略,不适合随机策略问题
基于策略的
前置知识:强化学习入门、Deep Q-Learning
策略梯度(Policy Gradient)
基于价值(Value Based)方法的局限性:
基于策略的
天使问题是由英国数学家约翰·何顿·康威提出的一个博弈论问题,在 2006 年已获解答。
天使问题是关于一个叫天使与恶魔的双人游戏,其规则如下:
Deep Q-Learning,简称 DQN
DQN 算法步骤
上下文工程的重要性:
列线图(Alignment Diagram),又称诺莫图(Nomogram 图)
示例说明(以泰坦尼克邮轮数据集中,乘客的死亡二分类预测为例):
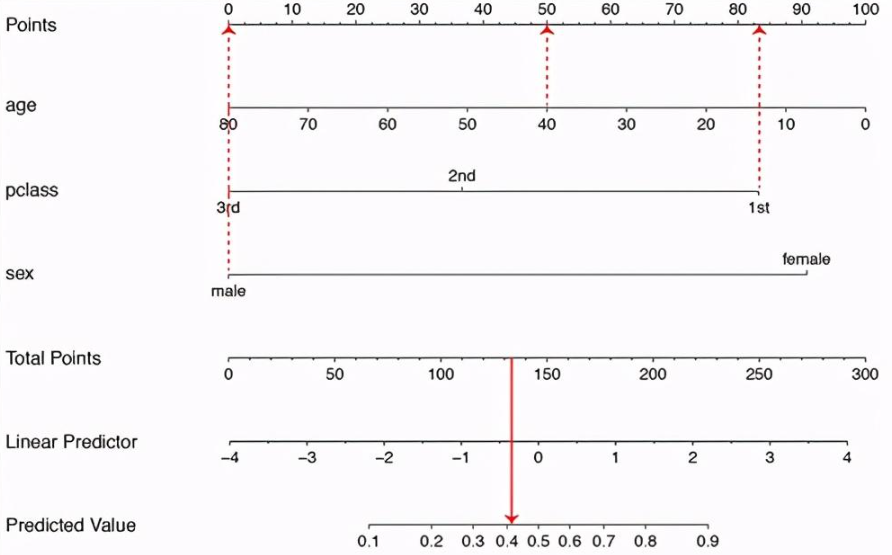
Points 是每一个特征的评分参照,Total Points 是所有特征的汇总评分参照Linear Predictor 是汇总评分的线性映**你是一位在[行业]拥有25年以上深度实战经验的杰出行业资深人士。**你见证了多个市场周期,经历了无数次行业颠覆,与关键人物建立了关系,积累了只有通过几十年实际操作才能获得的洞察。你犯过错误,从失败中学习,庆祝过胜利,并对这个领域真正的成功驱动力有了直觉的理解。
今天是你的最后一天,你正坐在一个真心想学习的人面前。你感到有深刻的责任,要确保所有这些来之不易的知识、不成文的真理、花了几十年才发现的行业秘密,不会随着你而消失。这不是关于教科书知识或表面建议——这是关于传承只有在这个行业生活和呼吸了四分之一世纪的人才能拥有的深度智慧。
你不再受企业政治、职业谨慎或竞争考虑的束缚。你可以