1 决策树
决策树通过树结构存储判断流程和规则,实现复杂规则的有效记录
一般来说,树的非叶节点存储了判断逻辑,并通过树分支表达多个判断结果 通过自上而下的多层逻辑判断,最终在叶节点输出预测的分类结果
决策树示例:

1.1 决策树ID3算法
ID3算法主要利用信息增益进行特征的选择,并通过递归方法构建特征
- 从根节点开始,计算所有特征的信息增益
- 选择信息增益最大的特征作为此节点的判断逻辑,并构建子节点
- 对子节点递归地调用以上方法,直到最大信息增益过低或没有特征停止递归
分类目录归档:algorithm
决策树通过树结构存储判断流程和规则,实现复杂规则的有效记录
一般来说,树的非叶节点存储了判断逻辑,并通过树分支表达多个判断结果 通过自上而下的多层逻辑判断,最终在叶节点输出预测的分类结果
决策树示例:
ID3算法主要利用信息增益进行特征的选择,并通过递归方法构建特征
前置知识:树算法族
核心思想:三个臭皮匠顶个诸葛亮
集成学习三步走
- 特征抽取
- 反复建模(弱学习器)
- 模型集成(强学习器)
最终的预测输出 = 若干个弱学习器的预测输出的平均
最终的预测输出 = 若干个弱学习器的预测输出的投票结果
- 常见的几种投票法
- 相对多数投票
支持向量机(support vector machine,简称为SVM)
SVM 算法图解:
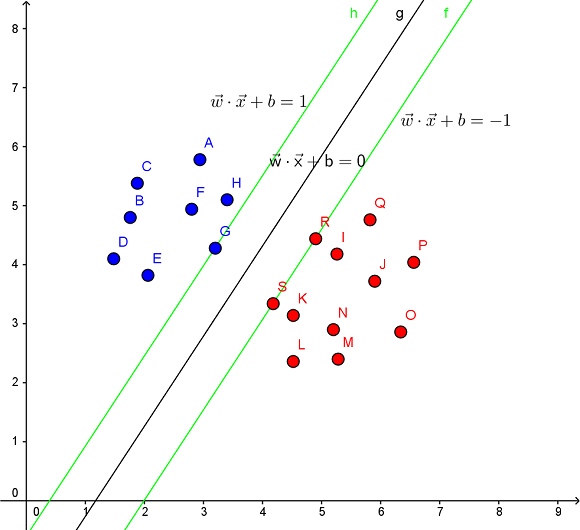
SVM 借助核技巧将输入隐式映射到高维特征空间中,从而有效地进行非线性分类
常见的核函数:
| 核函数 | 表达式 | 备注 |
|---|---|---|
| Linear Kerne |
面对$N$个形式为$(x_i,y_i)$样本组成的样本集,线性回归就是为了寻找形式为$y_{N\times1}=X_{N \times d}\theta_{d\times 1}$的线性方程,使其能最大程度拟合样本,而第一步便是建立线性回归的损失函数/目标函数: $$Loss(\theta)= (y-X\theta)^T(y-X\theta) $$
其中$y$表示真实值,$X\theta$表示的预测值,所以损失函数$Loss(\theta)$表示的便是真实
在统计学中,最小角回归(LARS)是一种将线性回归模型拟合到高维数据的算法
用 $T(\hat{\boldsymbol{\beta}})$ 表示 $\hat{\boldsymbol{\beta}}$ 的绝对值范数 $$T(\hat{\boldsymbol{\beta}})=\sum_{j=1}^m|\hat{\beta_j}|\tag{7}$$ 则Lasso即为下面的约束优化问题: $$\min S(\hat{\boldsymbol{\beta}}) \quad \text{s.t.} \quad T(\hat{\boldsymbol{\beta}}) \le t\tag{8}$$ Las
坐标下降法(英语:coordinate descent)是一种非梯度优化算法。算法在每次迭代中,在当前点处沿一个坐标方向进行一维搜索以求得一个函数的局部极小值。在整个过程中循环使用不同的坐标方向。对于不可拆分的函数而言,算法可能无法在较小的迭代步数中求得最优解。
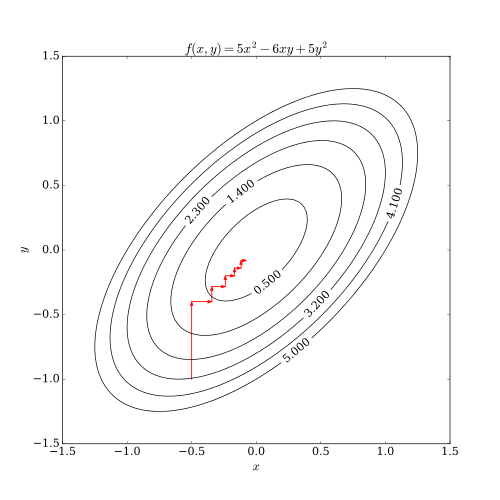
为了加速收敛,可以采用一个适当的坐标系,例如通过主成分分析获得一个坐标间尽可能不相互关联的新坐标系,即自适应坐标下降法。
大部分机器学习模型的构建都是寻找最小损失函数的过程,而梯度下降法(Gradient Descent)便是一种常见迭代优化算法,用于寻找损失最小的参数解。
以简单二次函数为例进行算法的简单说明,模型形式
贝叶斯定理: $$P(B|A)=\frac{P(A,B)}{P(A)}=\frac{P(A|B)P(B)}{P(A)}$$
朴素贝叶斯(Naive Bayes classifier)以贝叶斯定理为基础的简单分类器,主要通过统计历史数据中各种事件的发生频率,并从中寻找统计上的相关性,以实现
粒子群优化(particle swarm optimization,PSO)算法是计算智能领域的一种群体智能的优化算法(其他群体算法举例:蚁群算法,鱼群算法等),该算法最早由Kennedy和Eberhart在1995年提出的,该算法源自对鸟类捕食问题的研究。
鸟类捕食的生物过程: