1 理解环境变量
在所有 UNIX 、 类Unix系统和Windows系统中, 每个进程都有其特定的一组环境变量(Windows系统中的环境变量在命名、语法和用法上略有区别)
环境变量是进程运行的环境的一部分,子进程一般会继承其父进程的运行环境(除非手动的修改或删除),环境变量也是动态的,为进程提供了更多的灵活性
2 环境变量类型
临时性VS永久性
- 通过
export命令导入的环境变量是临时的,会立即生效但仅对当前终端有效 - 通过修改配置文件导入的环境变量是永久的,但是需要通过命令
sour
分类目录归档:学习
在所有 UNIX 、 类Unix系统和Windows系统中, 每个进程都有其特定的一组环境变量(Windows系统中的环境变量在命名、语法和用法上略有区别)
环境变量是进程运行的环境的一部分,子进程一般会继承其父进程的运行环境(除非手动的修改或删除),环境变量也是动态的,为进程提供了更多的灵活性
临时性VS永久性
export命令导入的环境变量是临时的,会立即生效但仅对当前终端有效sourINI:Initialization file的格式,最初为Windows系统中的基础配置文件格式
INI格式作为早期常见的配置文件格式,通常由节(Section)、键(key)和值(value)组成
缺点:不适合复杂的格式或多嵌套的情况
[localdb]
host = 127.0.0.1
user = root
password = 123456
port = 3306
database = mysql
Python内置con
将一幅图像中的坐标位置映射到另一幅图像中的新坐标位置
2D几何变换分类:
主成分分析(Principal components analysis,PCA),一种常用的线性降维方法
算法步骤:
图像理解:
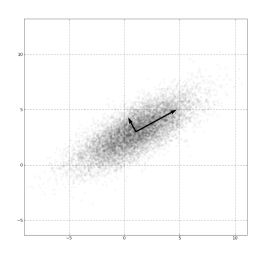 (图源:维基百科-主成分分析)
(图源:维基百科-主成分分析)
PCA 的优缺点分析:
尺度不变特征变换匹配算法(Scale Invariant Feature Transform 简称 SIFT)
SIFT算法常用来提取用于描述影像中的局部性特征,算法主要从空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量
算法过程:
期望最大化(Expectation-Maximum,简称EM)算法是一种机器学习常见基础算法
EM算法常用于处理存在隐变量的最大似然估计模型,训练过程简单描述如下:
以K-means聚类为例进行直观理解:
EM算法作为一种基础算法,广泛应用于多种算法模型的学习过程,比如:隐马尔可夫模型 HMM
这类算法思想在其他模型中也经常遇见,比
输入重定向:
<:将指定文件的内容作为前面命令的参数
输出重定向:
>:直接把输出覆盖保存到指定文件
>>:把输出尾部追加保存到指定文件
/dev/null
- 类Unix系统中的一个特殊的设备文件
- 作用是像垃圾桶一样接收一切写入其中的数据并丢弃
- 写入操作会提示成功,读取操作会返回一个EOF报错
用于不挂断地运行命令(关闭当前session不会中断程序,只能通过kill等命令删除) 默认情况下该程序的输出都会被重定向到nohup.out文件中,也可以通
本文内容主要摘自:
《Is something better than pandas when the dataset fits the memory?》
代码地址
性能对比主要围绕5个操作展开:
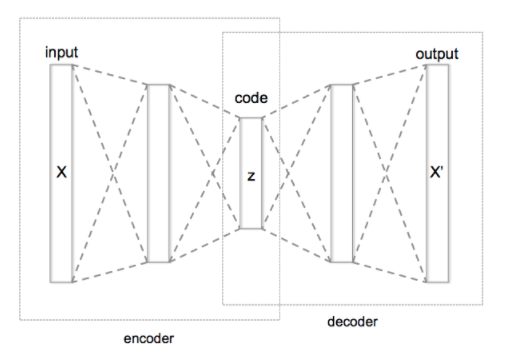 (图源:维基百科-自编码器)
(图源:维基百科-自编码器)