TabPFN 的主要特点:
- 一种面向小规模表格数据(样本量<=10000)的预训练 Transformer 模型
- 不同与以往基于 X 预测 Y 的传统模型,TabPFN 更类似于 AutoML 或者元学习的思路,其先基于真
分类目录归档:学习
TabPFN 的主要特点:
ASA 分级标准,指的是美国麻醉医师协会(ASA)于麻醉前根据
辛普森悖论 提醒我们在分析数据时要仔细考虑分组和混杂因素的影响,而因果推断的作用就是使用适当的方法识别和控制这些因素,从而可以更好地解释数据中的关系,并做出可靠的结论。
相关性与因果性:
贝叶斯神经网络(Bayesian neural networks, BNNs):
谵妄的定义:POD 是一种急性发作的、暂时性脑功能异常。POD 多数发生在术后 1 周内, 以注意力不集中、意识水平变化和认知功能急性改变为特征。POD 可增加患者术后其他并发症发生率、延长住院时间、增加医疗费用和 30d 再人院率, 从而影响患者预后。
谵妄的常见临床表现:
荟萃分析显示:脓毒症休克患者的住院死亡率为 39%,与评估的时间点无关
脓毒性休克的定义:持续低血压,尽管进行了适当的容量复苏(20-30 毫升/千克,2 升液体在 30 分钟内),仍然需要血管加压药物维持平均动脉压≥65 mm Hg 且血清乳酸水平大于 2 mmol/L;
脓毒性休克理解已从传统“血压降低”表象深入至“低灌注”病理生理本质
休克的原因:
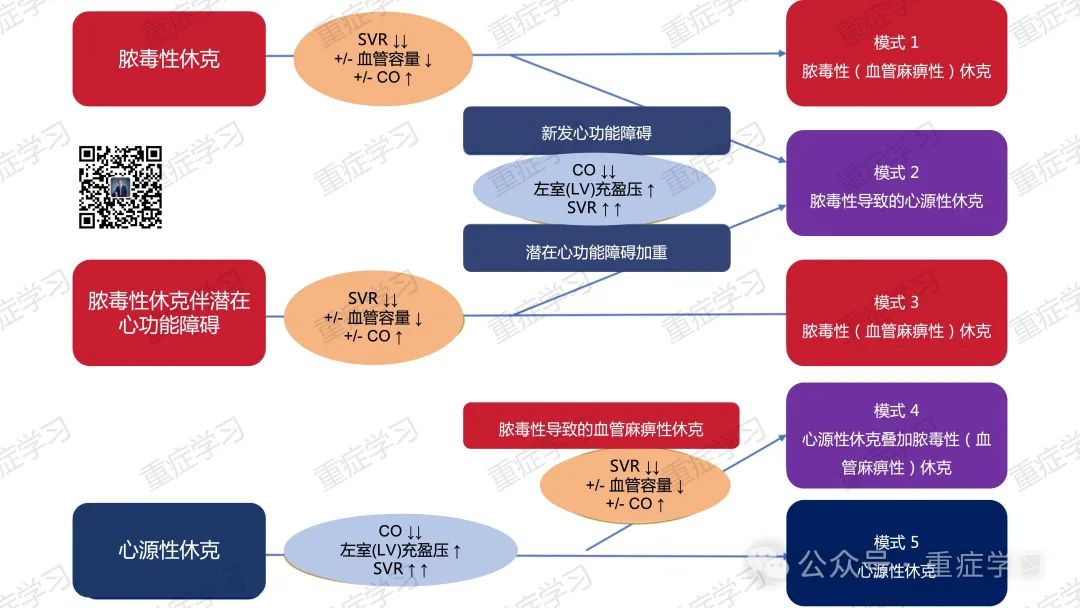
脓毒性休克和心源性休克的相互影响以及不同的演变过程:
液体治疗是围手术期管理的重要组成部分,其内容包括补充机体正常生理液体需要量以及麻醉和手术所导致的循环血容量改变和液体缺失,维持良好的组织灌注和内环境稳定,避免细胞代谢紊乱和器官功能损伤
围手术期推荐的常用液体治疗种类包括晶体液和胶体液
心源性休克是一种复杂的综合征:
心源性休克的定义(克学术研究联盟 SHARC)
急性肾损伤,导致肾脏结构或功能变化的损伤引起的肾功能减退
AKI 诊断标准:48h 内肌酐升高≥0.3 mg/dl,或在前 7 天内超过基线的 1.5 倍
AKIN 标准,为血清肌酐比术前水平增加绝对值>0.3 mg/dL,增加 ≧ 50%,或每小时尿量<0.5 mL/kg 持续 6 小时以上
急性肾损伤(AKI)的理解: