- 易感者(Susceptible):存在感染风险的正常人群,用符号$S(t)$来表示
- 感染者(Infective):已经被感染的人群,用符号$I(t)$ 来表示
- 免疫者(Recovered):因为隔离/疫苗/病愈等原因而具备免疫力的人群
- 暴露者(Exposed):指接触过感染者,但暂无感染能力的人群(潜伏期)
1 SI模型
假设与定义:
- 总人口为$N$,不考虑人口的出生与死亡(即总人口不变)
- 不考虑无感染风险的人群,不
分类目录归档:algorithm
假设与定义:
瑞利熵(Rayleigh quotient)函数定义如下: $$R(A,x)=\frac{x^HAx}{x^Hx}$$
瑞利熵$R(A,x)$的重要性质: $$\lambda_{min}\leq R(A,x)\leq \lambda_{max}$$
拉普拉斯特征映射(Laplacian Eigenmaps,简称LE)是一种基于图的降维算法
LE算法核心思想:在低维空间内,尽可能保证局部样本间的结构不变
LE算法步骤:
LE算法分析:
谱聚类(spectral clustering):一种基于图的聚类算法
前置知识:图论基础概念、图论基础#3.1 理解拉普拉斯矩阵
核心思想:将数据转化为图的形式,距离近的数据间对应的边权重高,距离远的数据间对应的边权重低。之后通过切图的方式,使得不同子图间的边权值和尽可能低,子图内部的边权值和尽可能高,从而达到聚类的目的
核心思想:把每个样本看作一个节点,然后构建任意两点$(x_i,x_j)$间权重边$w_{ij}$
方法1
在最优化问题的求解过程中常利用到函数梯度及其高阶信息
牛顿法(Newton's method)又称为牛顿-拉弗森方法(Newton-Raphson method)
牛顿法借助泰勒级数的低阶展开,寻找方程$f(x)=0$的根(因此也被称为切线法)
牛顿法计算步骤:
将一幅图像中的坐标位置映射到另一幅图像中的新坐标位置
2D几何变换分类:
主成分分析(Principal components analysis,PCA),一种常用的线性降维方法
算法步骤:
图像理解:
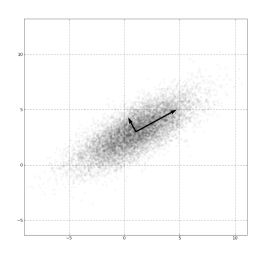 (图源:维基百科-主成分分析)
(图源:维基百科-主成分分析)
PCA 的优缺点分析:
尺度不变特征变换匹配算法(Scale Invariant Feature Transform 简称 SIFT)
SIFT算法常用来提取用于描述影像中的局部性特征,算法主要从空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量
算法过程:
期望最大化(Expectation-Maximum,简称EM)算法是一种机器学习常见基础算法
EM算法常用于处理存在隐变量的最大似然估计模型,训练过程简单描述如下:
以K-means聚类为例进行直观理解:
EM算法作为一种基础算法,广泛应用于多种算法模型的学习过程,比如:隐马尔可夫模型 HMM
这类算法思想在其他模型中也经常遇见,比
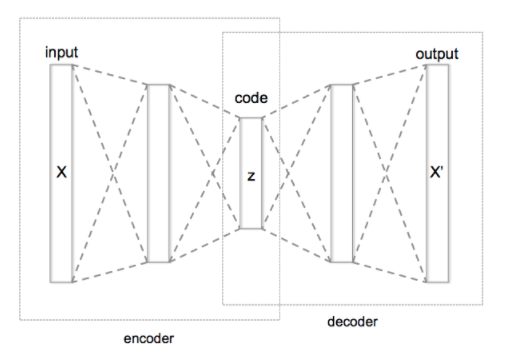 (图源:维基百科-自编码器)
(图源:维基百科-自编码器)