MCP 模型上下文协议
MCP 协议基本架构(图源)
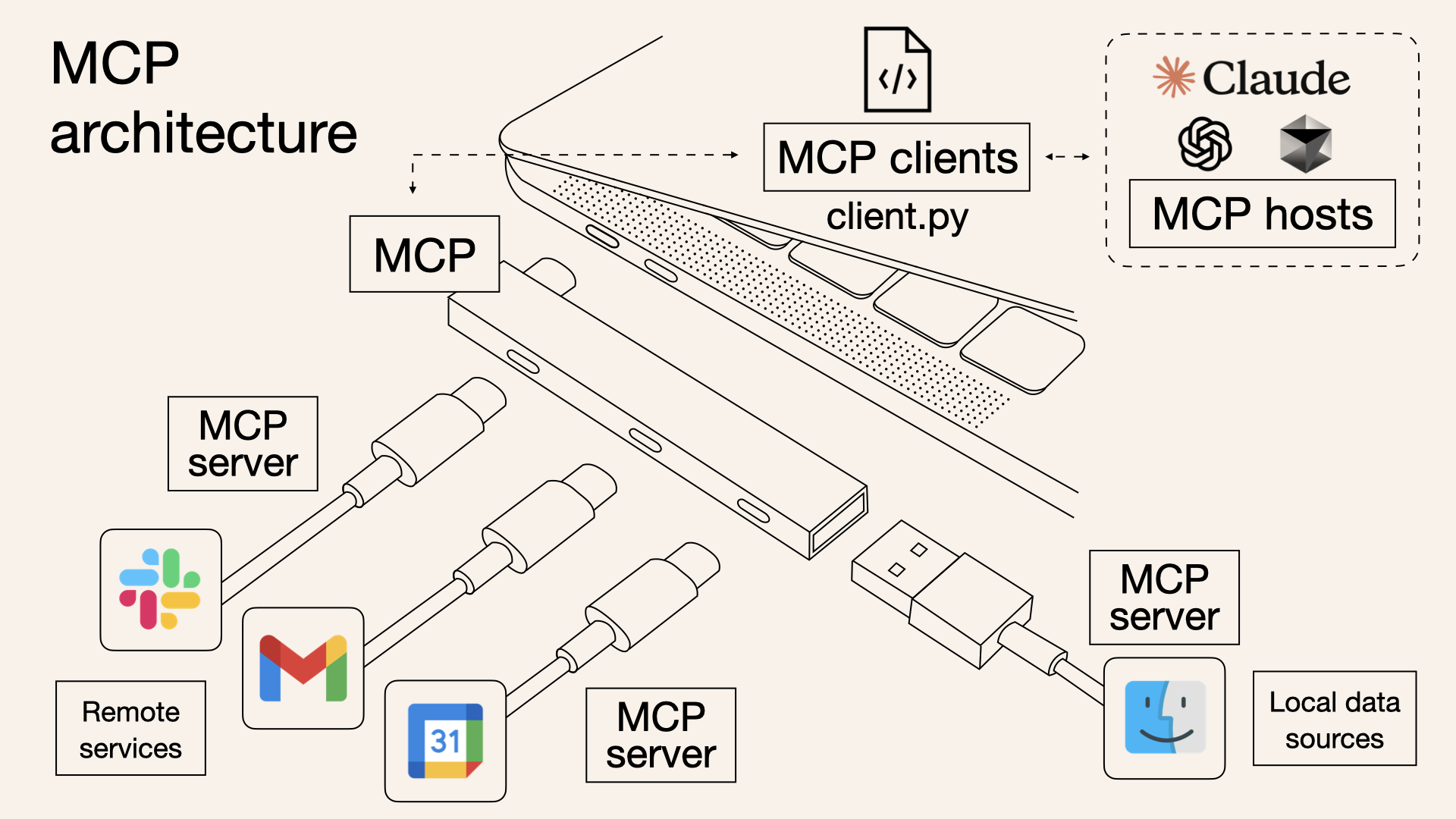
- 由 Anthropic 提出,用于标准化 LLMs 与外部系统交互的接口
- 开发者能以统一的方式将大模型对接到各种数据源和工具
- MCP 采用了经典的 C/S 架构,包含主机、服务端和客户端三部分
目前 MCP 协议已得到了广泛的生态支持,兼具通用性和灵活性
MCP 底层通信
MCP 的会话管理
- 通过一个健壮的两步握手(i
分类目录归档:学习
MCP 协议基本架构(图源)
目前 MCP 协议已得到了广泛的生态支持,兼具通用性和灵活性
MCP 的会话管理
过敏性休克
美国过敏性休克的终身患病率估计在 0.05%至 2%之间
过敏性休克的临床标准:美国国立过敏和传染病研究所(NIAID)金标准
UMAP 算法
UMAP 定义的概念解释与补充:
t-SNE 算法
算法过程概述:
Pydantic 是目前最流行的 Python 数据验证工具
Pydantic 的特点
调查问卷分析的一般流程:
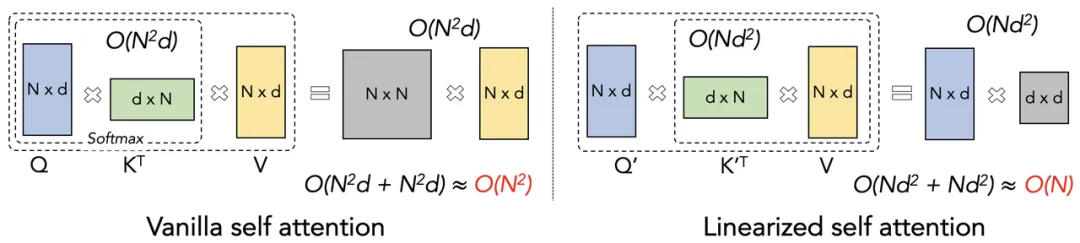
前置知识: 10.《动手学深度学习》注意力机制
原始 Tansformer(左) VS 线性 Tansformer(右):
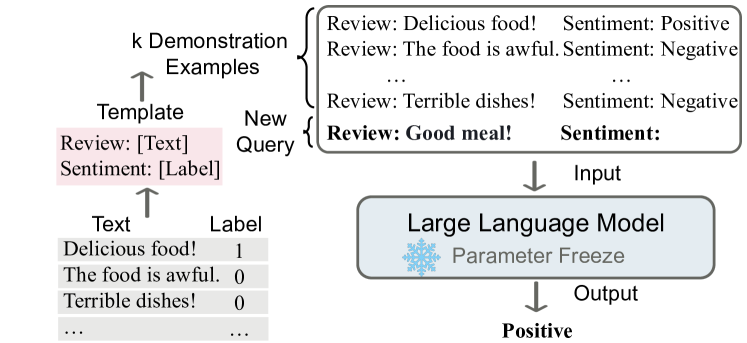
大语言模型(LLMs)的上下文学习:经过预训练的 LLMs 能根据文本提示或任务示例来直接对下游任务进行预测,而无需更新模型权重,这种能力也被称为上下文学习(in-context learning,ICL)或语境学习
简单来说,ICL 就是在不更新模型参数的前提下,通过输入经典示例作为提示来增强模型的能力
以情感分析为例,来说明 ICL 的一般流程(图源):
ICL 的分类:
LSH(locality sensitivity Hashing,局部敏感性哈希)算法
以相似文档检索为例,说明 LSH 的算法过程
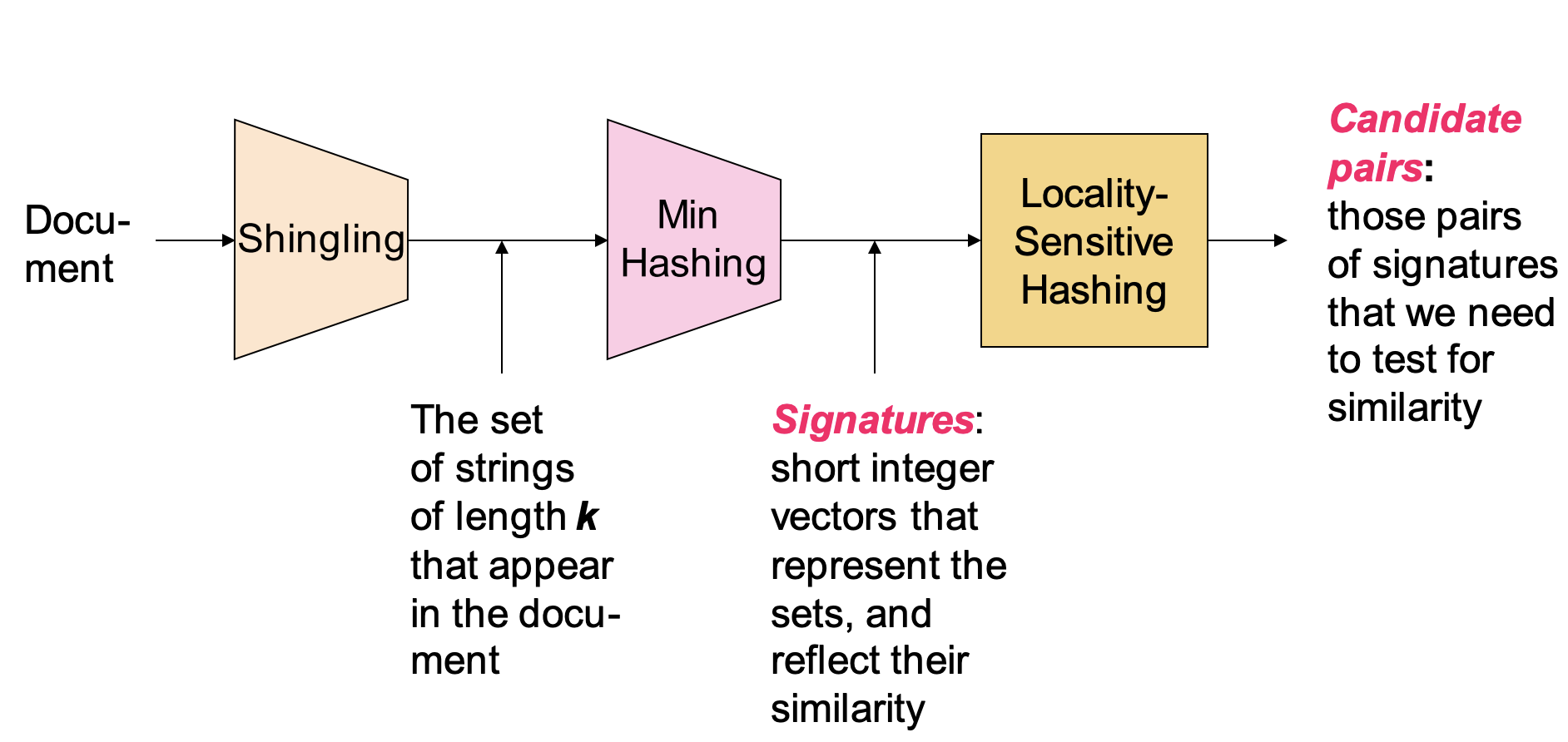
Shingling,文档进行向量化表示
Min-Hashing,对文档信息进行降维
TabPFN 的主要特点: