量子:量子是组成物质和能量的离散的基本单位。有别于传统经典物理中的概念,在微观世界中物质与能量会从一个个连续的量变成一个个离散的量(就像人走上台阶一样,人只能站在整数台阶上,而不能站在第 1.6 个或 2.4 个台阶上,因为不稳定)。这种离散的物理学概念就是量子~
基础公设
量子力学的五个基础公设
- 态矢量公设/量子态公设:量子系统的状态由希尔伯特空间中的态矢量描述,态矢量视为系统的“信息载体”,包含了关于系统所有可能测量结果的信息;波函数是态矢量的一种具体表示
- 可观察量公设:每个可观察物理量(
量子:量子是组成物质和能量的离散的基本单位。有别于传统经典物理中的概念,在微观世界中物质与能量会从一个个连续的量变成一个个离散的量(就像人走上台阶一样,人只能站在整数台阶上,而不能站在第 1.6 个或 2.4 个台阶上,因为不稳定)。这种离散的物理学概念就是量子~
量子力学的五个基础公设
量子相位:描述量子态的复数波函数的一个基本特征,即 $\Psi(x, t) = A \times e^{i \psi (x, t)}$ 中的 $\psi (x, t)$;相位描述信号波形变化的度量,通常以度 (角度)作为单位,也称作相角
量子叠加:量子系统的基本性质,描述量子态可同时处于多个可能状态的线性组合
量子相干:量子叠加的一种形式,描述了特定基底下定义不同叠加分量间的相位关系;相干表现为干涉现象(比如双缝干涉实验),即波函数在不同路径上的叠加;量子系统与环境纠缠导致信息泄露,会引起随机相位扰动导致叠加态分量相位关系破坏,这一过程也被称为去
XML 格式的好处:
原始提示词:
你是一个资深的文学家,你正在阅读一篇文章,请仔细阅读,然后基于文章的内容,按如下格式返回总结:
## 文章概览
[对文章的整体总结]
## 核心观点
* 观点1
* 观点2
* 观点n
## 关键人物
如果文章中提到了金融领域的任何人物,需要把他们提取出来,如果没有,就忽略这一项
## 规则
在总结的时候,你必须遵守如下规则:
1. 如果文章与金融领域无关,直MCP 协议基本架构(图源)
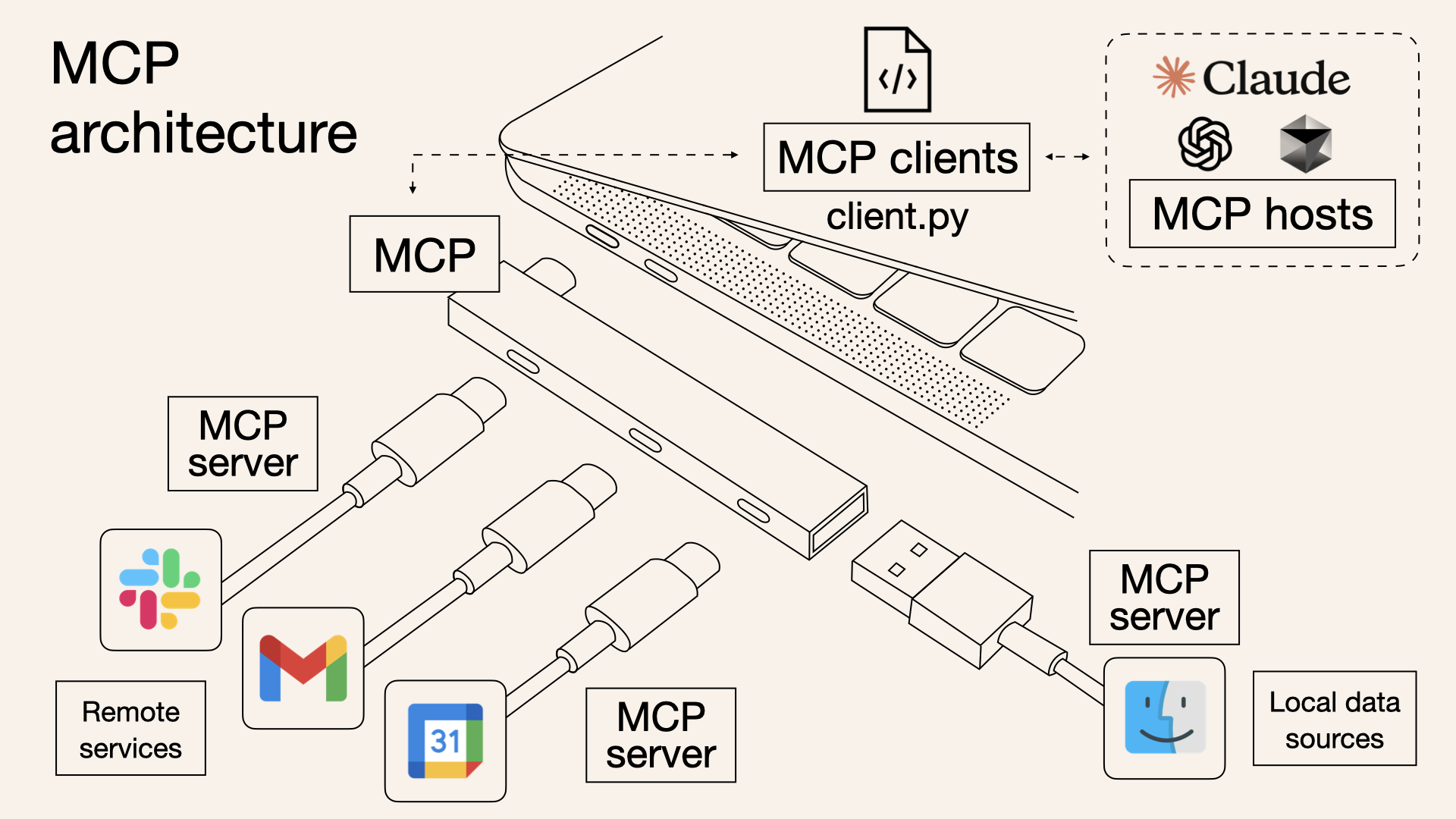
目前 MCP 协议已得到了广泛的生态支持,兼具通用性和灵活性
MCP 的会话管理
手机监听的几种方式:
获取麦克风权限用于窃听的方法,在经济成本和技术能力层面都不现实
根据字节的一篇科普文章可知
过敏性休克
美国过敏性休克的终身患病率估计在 0.05%至 2%之间
过敏性休克的临床标准:美国国立过敏和传染病研究所(NIAID)金标准