驱蚊灭虫
驱蚊:
- 在电风扇的叶子上洒上几滴风油精,随着风叶的不断转动,可使满室清香,而且有驱赶蚊子的效果。
杀蟑螂:硼酸+土豆泥(低成本,没试过)、拜灭士胶饵(有效,但对于顽固场景只能起到抑制作用)、呋虫胺(有效成份)、蟑螂屋(效果一般,不推荐)、搬家(成本很高,但租房党还是推荐这个方案)、专业消杀(成本较高,入住前可考虑进行一次)、白额高脚蛛(= =)
顽固污渍
胶水:用 502 胶水的时候,如果不小心把手给粘上了,千万别硬撕,可以喷点花露水,就能把胶水洗掉了
油渍:衣物沾上了油渍,洗之前在上面
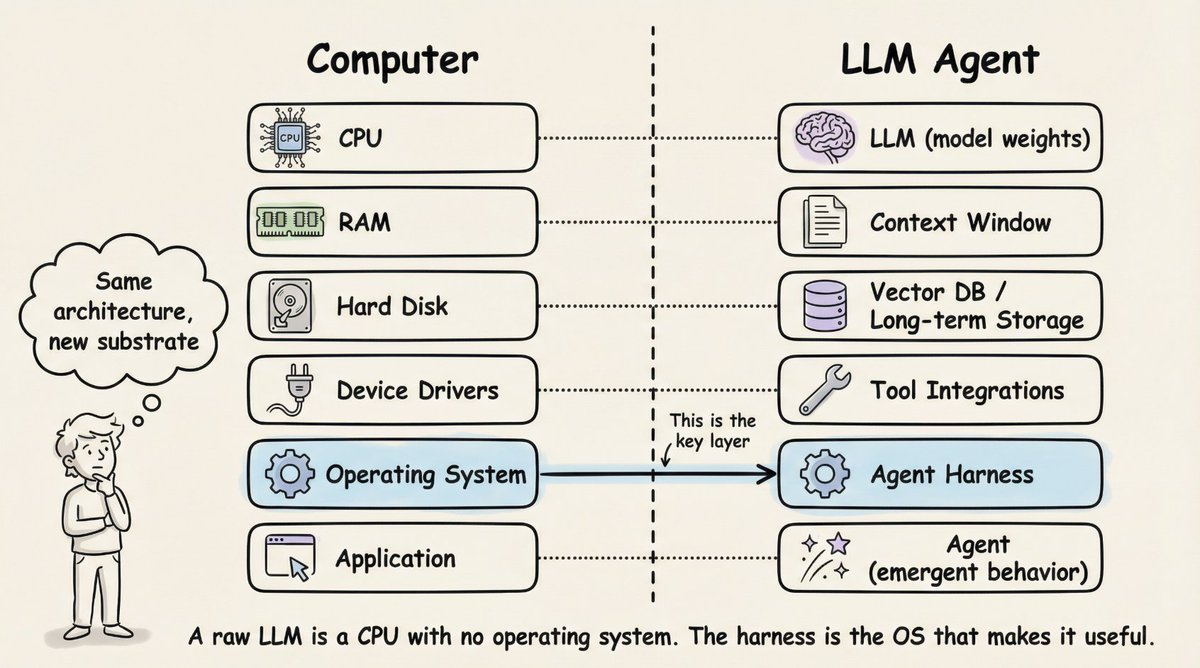 图源 - 《Scaffolded LLMs as Natural Language Computers》 by Beren Millidge
图源 - 《Scaffolded LLMs as Natural Language Computers》 by Beren Millidge