1 推荐系统的任务与评价
推荐系统可以建模为二分图(bipartite graph)
- 具有两种类型的节点——用户(user)和项(item)
- 边用于连接用户和项,表示二者间的互动(比如点击、购买或评论)
任务:给定历史图,预测每个用户未来将产生的交互项(链接预测问题)
前置知识:推荐排序模型评价指标
基于嵌入表示的推荐系统建模思路
- 对于每一个用户 $u$,基于编码器生成对应的用户嵌入表示
- 对于每一个可交互项 $v$,基于编码器
分类目录归档:课程
推荐系统可以建模为二分图(bipartite graph)
任务:给定历史图,预测每个用户未来将产生的交互项(链接预测问题)
前置知识:推荐排序模型评价指标
基于嵌入表示的推荐系统建模思路
子图(subgraphs)是构建图的基础块,能够描述和区分图网络
给定图 $G=(V,E)$,可以给出 2 种方式定义子图 $G'=(V',E')$
子图的定义方式 1:节点诱导子图(Node-induced subgraph)
本小节的示例均围绕以下知识图展开:
常见的三种知识图推理类型:

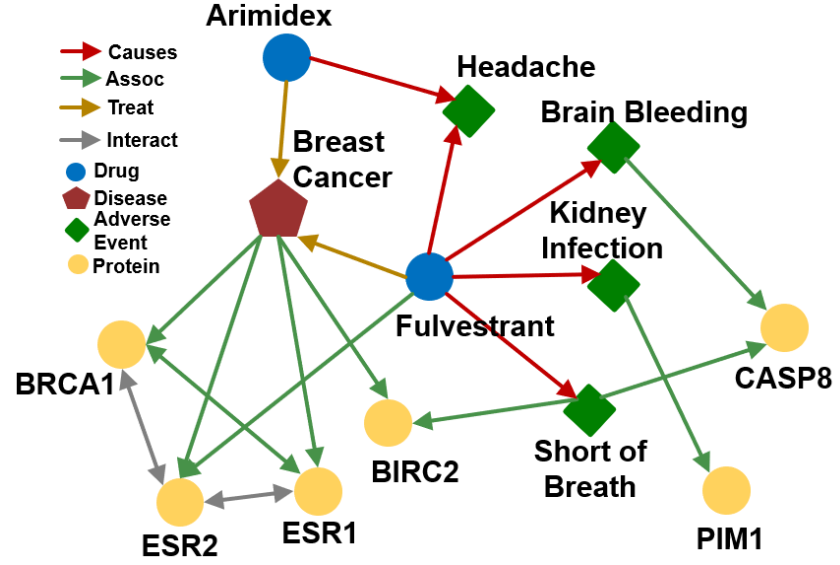
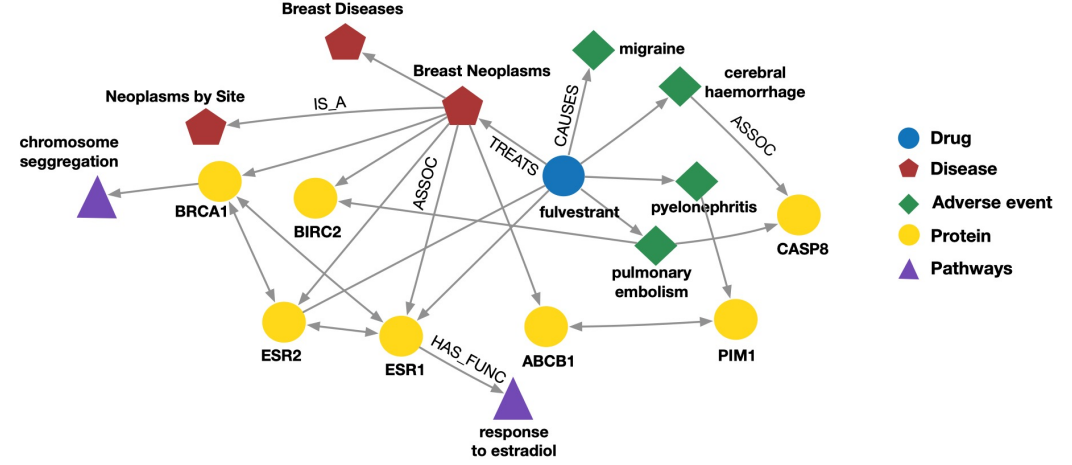
知识图(Knowledge graph):以图的形式存储知识
知识图示例:生物知识图(蛋白质/药物/疾病/不良事件)
知识图应用:信息检索服务、问答和对话
常见的开源 KG :知识图数据资源
这类知识图一般是百万级别的,存在很多边的缺失(考虑补齐)
比
异构图(Heterogeneous Graph),存在不同类型的节点和边
即节点和边至少有一个具有多种类型,常见于知识图谱的场景
举例:引文网络
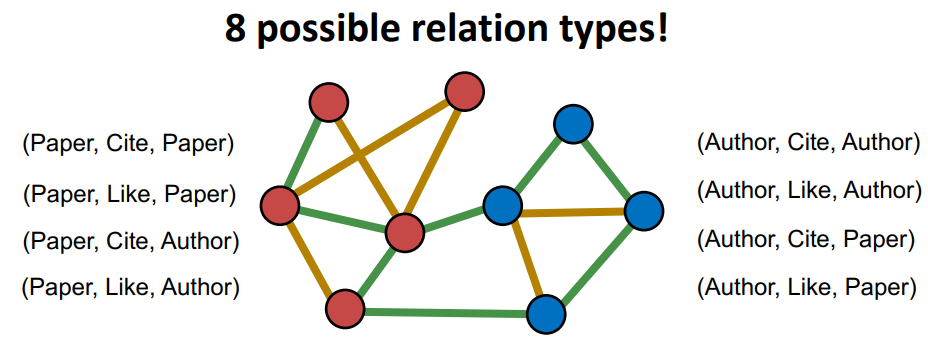
从异构图到标准图:
one-hot 形式的特征,以此区分类型[1, 0] 附加到每个“作者节点”;将特征 [0, 1] 附加到每个“纸节点”关键问题:GNN 节点嵌入能否区分不同节点的局部邻域结构?
GNN 通过邻域定义的计算图生成节点嵌入:
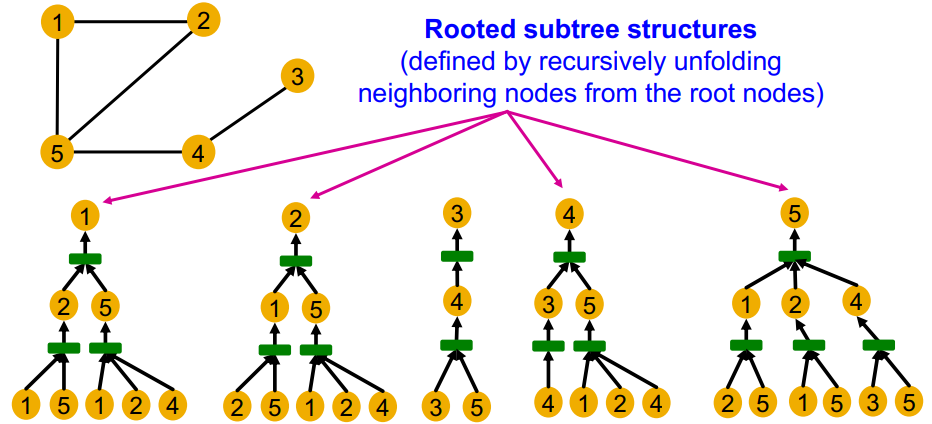
由于 GNN 主要依赖节点特征,而不考虑节点 ID
因此 GNN 无法区分位置同构的节点(节点 1 和节点 2)
图训练的完整 Pipeline:
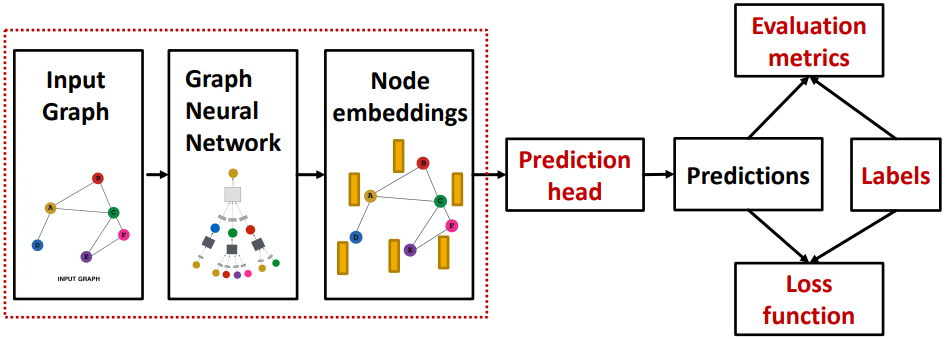
不同的任务级别需要不同的预测头(Prediction head)
$$ \widehat{\boldsymbol{y}}_v=\mathrm{Head}_{\mathrm{node}}(\mathbf{h}_v^{(L)})=\mathbf{W}^{(H)}\mathbf{h}_v^{(L)} $$
图神经网络(GNN)的通用框架:
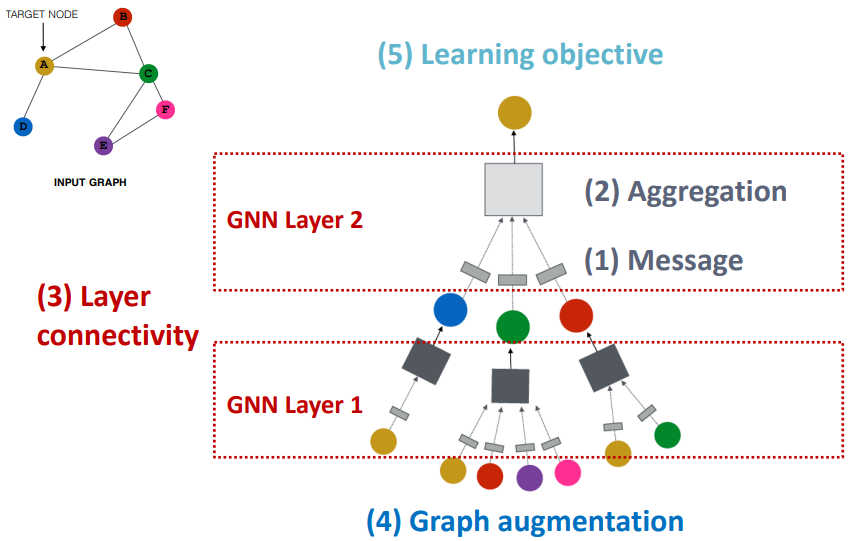
所以单层 GNN 的计算过程可表示如下: $$ \begin{aligned} \mathbf{m}_u^{(l)}&=\mathrm{MSG}^{(l)}\left(\math
图数据的复杂性:
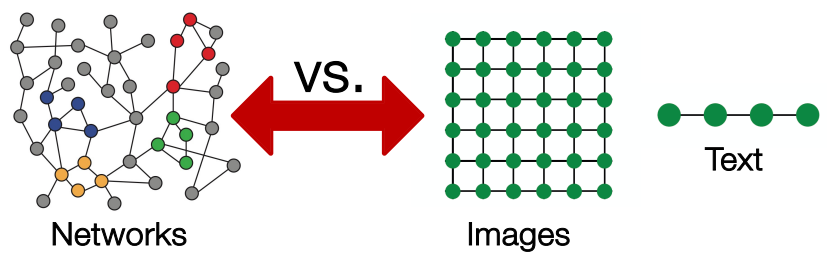
直接将邻接矩阵或节点特征输入到传统神经网络的问题:
置换不变性 vs 置换等价性
“压缩现代性”,这个词很生动、贴切。中(含台湾)、日、韩三个国家的普通民众的生活都有明显的“压缩”特征:
1、住房是压缩的。美国人住别墅,中日韩绝大多数人住公寓。东亚城市人口密度远高于美国,也高于欧洲。这节约了土地,也导致普通人的个人空间严重不足;
2、学习是压缩的。“做题家”,这一个词描述了以高考为人才选拔的高压模式。进大学前,想考个好大学、好专业,那就只有拼命做题;
3、工作是压缩的。“加班、超时劳动”被普遍接受,只要老板给高一点的加班费,打工者对加班一般持欢迎与接受的态度。但这也极大地减少了可用于关心家庭、个人再学习、社交等一系列的工作之外的时间;
4、生育也是压缩的。一对夫妻,生一